Data warehousing is a method of organizing and compiling data into one database, whereas data mining deals with fetching important data from databases. Data mining attempts to depict meaningful patterns through a dependency on the data that is compiled in the data warehouse.
A data warehouse is where data can be collected for mining purposes, usually with large storage capacity. Various organizations’ systems are in the data warehouse, where it can be fetched as per usage.
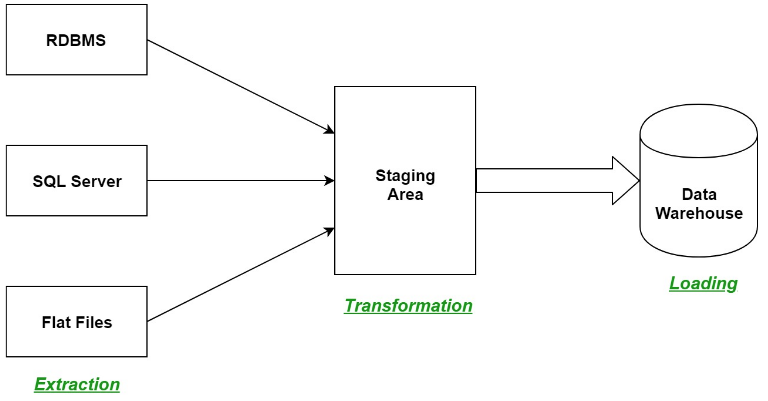
Source 🡪 Extract 🡪Transform 🡪 Load 🡪 Target.
(Data warehouse process)
Data warehouses collaborate data from several sources and ensure data accuracy, quality, and consistency. System execution is boosted by differentiating the process of analytics from traditional databases. In a data warehouse, data is sorted into a formatted pattern by type and as needed. The data is examined by query tools using several patterns.
Data warehouses store historical data and handle requests faster, helping in online analytical processing, whereas a database is used to store current transactions in a business process that is called online transaction processing.
It provides you with important data about a specific subject like suppliers, products, promotion, customers, etc. Data warehousing usually handles the analysis and modeling of data that assist any organization to make data-driven decisions.
Different heterogeneous sources are put together to build a data warehouse, such as level documents or social databases.
The data collected in a data warehouse is identified with a specific period.
This means the earlier data is not deleted when new data is added to the data warehouse. The operational database and data warehouse are kept separate and thus continuous changes in the operational database are not shown in the data warehouse.
Data warehouses help analysts or senior executives analyze, organize, and use data for decision making.
It is used in the following fields:
In this process, data is extracted and analyzed to fetch useful information. In data mining hidden patterns are researched from the dataset to predict future behavior. Data mining is used to indicate and discover relationships through the data.
Data mining uses statistics, artificial intelligence, machine learning systems, and some databases to find hidden patterns in the data. It supports business-related queries that are time-consuming to resolve.

It is used to find which insurance claims, phone calls, debit or credit purchases are fraud.
Existing marketplace trends are analyzed,which provides a strategic benefit as it helps in reduction of costs, as in manufacturing per demand.
It can predict the market and therefore help to make business decisions. For example: it can identify a target market for a retailer, or certain types of products desired by types of customers.
It is used to fetch the appropriate information from the dataset and to segregate different classes that are present in the dataset. Below are the classification models.
Sample code for Support Vector Machine:
1 2 3 4 5 6 7 8 9 10 11 12From sklearn.svm import SVC sv = SVC() sv.fit(x_train, y_train) print(‘Svm classifier Accuracy for training data: < : .3 f >’.format(sv.score(x_train, y_train)) print(‘Svm classifier on test data: < : .3 f >’.format(sv.score(x_test, y_test))
Output:
Svm classifier Accuracy for training data: 0.613
Svm classifier on test data: 0.331
It is used to find similarities in data by putting related data together and helping to identify different variations in the dataset. It helps to find hidden patterns. An example of clustering is text mining, medical diagnostics, etc.
They are used to identify a connection of two or more items. For example, if-then scenarios of items that are frequently purchased in tandem in a grocery store can calculate the proportion of items that are bought by customers together. Lift, confidence, and support are techniques used in association rules.
It is used to identify patterns that do not match the normal behavior in the data, as the outlier deviates from the rest of the data points. It helps in fraud detection, intrusion, etc. Boxplot and z-score are ways to detect outliers.
Sample code for boxplot:
1 2Import seaborn as sns sns.boxplot(df_data[‘DIS’])
Output:
